Hoy retomo un tema relacionado con MySQL que la semana pasada no pude terminar por culpa de un error bastante serio de Google. No voy a hablar directamente de MySQL, pero sí voy a desahogarme con un problemilla (¡qué típico!) que he tenido a la hora de acceder a esta base de datos a través de programación. Sirva como adelanto comentar que este problemilla es extrapolable a todas las bases de datos del mercado; sin embargo, como las pruebas han sido contra MySQL, le daremos el dudoso honor de aparecer en mi post a ella ;-).
El caso es que la semana estuve midiendo tiempos y rendimiento de diferentes sentencias DML lanzadas contra MySQL. Más que nada, me interesaba analizar el comportamiento de los procedimientos almacenados o stored procedures que MySQL soporta a partir de la versión 5.0, frente a las clásicas sentencias en texto plano de select, insert, update y delete. Aunque existen herramientas tipo query analyzer que exprimen todo el jugo a cada consulta y miden tiempos y rendimiento de manera bastante precisa, me apetecía medir tiempos desde el mismísimo campo de batalla, desde la trinchera del programador, a pie de código. Inmejorable ocasión por tanto para probar MySQL Connector/NET 5.2 (última versión de este conector disponible a día de hoy) desde una aplicación de consola dummy programada en C#. Aparte de que quería probar este conector, tiene su lógica hacerlo de esta manera, ya que hoy en día toda aplicación que necesita acceder a base de datos utiliza conectores de diversos tipos dependiendo de la tecnología y lenguaje de programación que se esté utilizando.
Sin más preámbulos ni rollos macabeos, me centraré (por fin) en narrar lo que me pasó durante estas pruebas realizadas contra una base de datos MySQL remota, aunque dentro de las misma red que mi equipo de trabajo. Como siempre, todas estas pruebas y comparaciones suelen empezar suavecito, con sentencias select no demasiado complicadas, 1000 inserciones en una tabla, etc. Hasta aquí todo bien, tiempos parecidos, incluso ligeramente mejores para las queries en texto plano. Palabras mayores, paso a ejecutar un programita que realiza 100000 (cien mil) inserts en texto plano dentro de un bucle for en C#, es decir, ni más ni menos que 100000 llamadas a ExecuteNonQuery(). La ejecución tarda un rato, casi dos minutos, pero va bien, las filas son insertadas como Dios manda (¿Cómo manda Dios?).
Pasamos entonces a ver qué tal funciona lo mismo, pero haciendo una única llamada desde código al método ExecuteNonQuery(). ¿Cómo? Llamando (a gritos) a un stored procedure que realiza las mismas inserciones, aunque en un loop interno definido en el propio procedimiento almacenado, no a nivel de código cliente. ¡Vamos allá!
 ¡Pues va a ser que ha petado! A ver qué dice el error lanzado por el conector..."Fatal error encountered during command execution". Buff, ¡qué mal rollo Arroyo! Sinceramente, me he quedado igual o peor, no tengo ni idea de qué está pasando, y el error lanzado no es de gran ayuda, como ocurre desgraciadamente muchas veces.
¡Pues va a ser que ha petado! A ver qué dice el error lanzado por el conector..."Fatal error encountered during command execution". Buff, ¡qué mal rollo Arroyo! Sinceramente, me he quedado igual o peor, no tengo ni idea de qué está pasando, y el error lanzado no es de gran ayuda, como ocurre desgraciadamente muchas veces.
Vuelvo a ejecutar varias veces lo mismo con idéntico resultado, hasta que me apiado y paulatinamente voy bajando el número de inserciones del procedimiento almacenado hasta llegar a un punto en que ¡funciona! ¿Tendrá MySQL un límite de memoria/hilos/procesos en los procedimientos almacenados? No creo..., entonces, ¿será cosa del conector? Mientras me hago esta última pregunta me quedo mirando fijamente la consola, concretamente mi atención se centra en el tiempo cronometrado (por mí) que se muestra tras el error, 30 segundos y pico. ¡Ajá! Ya caigo..., me suena que las sentencias SQL tienen un timeout, es más, me suena que ese timeout suele tener por defecto un valor de 30 segundos. Vamos a tirar de la ayuda, que para algo la suelen realizar...
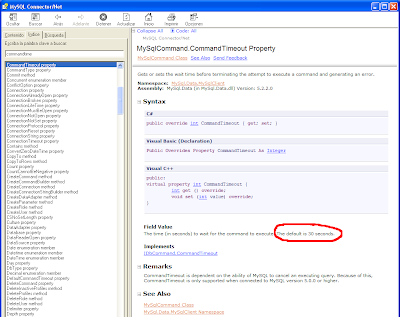 Efectivamente, confirmado queda que el comando para atacar la base de datos tiene un timeout por defecto de 30 segundos, lo que implica que si el comando no termina, se dispara un error. Claro, ahora todo coincide ya que seguramente la ejecución del stored procedure dura más de 30 segundos, lanzándose la excepción nada aclarativa recibida. ¿Solución? Establecer un valor más alto para dicho timeout. Aunque no se recomienda tocar este parámetro ya que es difícil que la ejecución de una query o stored procedure dure más de 30 segundos (excepto en las monstruosas transacciones y procesos batch que realizan bancos y demás), esta vez vamos a añadir una simple línea de código C# asignando un valor entero muy alto al timeout del command, pa' cubrirnos las espaldas ;-).
Efectivamente, confirmado queda que el comando para atacar la base de datos tiene un timeout por defecto de 30 segundos, lo que implica que si el comando no termina, se dispara un error. Claro, ahora todo coincide ya que seguramente la ejecución del stored procedure dura más de 30 segundos, lanzándose la excepción nada aclarativa recibida. ¿Solución? Establecer un valor más alto para dicho timeout. Aunque no se recomienda tocar este parámetro ya que es difícil que la ejecución de una query o stored procedure dure más de 30 segundos (excepto en las monstruosas transacciones y procesos batch que realizan bancos y demás), esta vez vamos a añadir una simple línea de código C# asignando un valor entero muy alto al timeout del command, pa' cubrirnos las espaldas ;-).
 Compilamos, y ¡allá vamos de nuevo!
Compilamos, y ¡allá vamos de nuevo!
 ¡Voilá! Como se puede apreciar en la imagen de arriba, las 100000 inserciones se han realizado perfectamente, en un tiempo ligeramente inferior a las 100000 inserciones realizadas "a pelo".
¡Voilá! Como se puede apreciar en la imagen de arriba, las 100000 inserciones se han realizado perfectamente, en un tiempo ligeramente inferior a las 100000 inserciones realizadas "a pelo".
Como adelantaba al principio del post, aunque en este caso particular el ejemplo se ha desarrollado con el conector de .NET para MySQL, esto mismo sirve para otros conectores, tanto a MySQL, como a Oracle, SQL Server, Sybase, o el repositorio de datos que sea. De hecho, si no me equivoco, todos los conectores a base de datos vienen por defecto con un timeout por comando de 30 segundos, tiempo más que suficiente en el 99.99% de los casos, y si no anda Lonifasiko por ahí cerca con ganas de marcheta ;-).
Tened en cuenta por tanto que el timeout en los accessos a base de datos existe, y aunque rara vez se da, hay casos en los que se supera y es necesario reajustar su valor manualmente por código. Soy el primer timeout-breaker, o ¿tiene alguien alguna otra experiencia similar que contar con otro conector hacia MySQL o hacia otra base de datos? Seguro que sí...
Pasamos entonces a ver qué tal funciona lo mismo, pero haciendo una única llamada desde código al método ExecuteNonQuery(). ¿Cómo? Llamando (a gritos) a un stored procedure que realiza las mismas inserciones, aunque en un loop interno definido en el propio procedimiento almacenado, no a nivel de código cliente. ¡Vamos allá!
 ¡Pues va a ser que ha petado! A ver qué dice el error lanzado por el conector..."Fatal error encountered during command execution". Buff, ¡qué mal rollo Arroyo! Sinceramente, me he quedado igual o peor, no tengo ni idea de qué está pasando, y el error lanzado no es de gran ayuda, como ocurre desgraciadamente muchas veces.
¡Pues va a ser que ha petado! A ver qué dice el error lanzado por el conector..."Fatal error encountered during command execution". Buff, ¡qué mal rollo Arroyo! Sinceramente, me he quedado igual o peor, no tengo ni idea de qué está pasando, y el error lanzado no es de gran ayuda, como ocurre desgraciadamente muchas veces.Vuelvo a ejecutar varias veces lo mismo con idéntico resultado, hasta que me apiado y paulatinamente voy bajando el número de inserciones del procedimiento almacenado hasta llegar a un punto en que ¡funciona! ¿Tendrá MySQL un límite de memoria/hilos/procesos en los procedimientos almacenados? No creo..., entonces, ¿será cosa del conector? Mientras me hago esta última pregunta me quedo mirando fijamente la consola, concretamente mi atención se centra en el tiempo cronometrado (por mí) que se muestra tras el error, 30 segundos y pico. ¡Ajá! Ya caigo..., me suena que las sentencias SQL tienen un timeout, es más, me suena que ese timeout suele tener por defecto un valor de 30 segundos. Vamos a tirar de la ayuda, que para algo la suelen realizar...
 Efectivamente, confirmado queda que el comando para atacar la base de datos tiene un timeout por defecto de 30 segundos, lo que implica que si el comando no termina, se dispara un error. Claro, ahora todo coincide ya que seguramente la ejecución del stored procedure dura más de 30 segundos, lanzándose la excepción nada aclarativa recibida. ¿Solución? Establecer un valor más alto para dicho timeout. Aunque no se recomienda tocar este parámetro ya que es difícil que la ejecución de una query o stored procedure dure más de 30 segundos (excepto en las monstruosas transacciones y procesos batch que realizan bancos y demás), esta vez vamos a añadir una simple línea de código C# asignando un valor entero muy alto al timeout del command, pa' cubrirnos las espaldas ;-).
Efectivamente, confirmado queda que el comando para atacar la base de datos tiene un timeout por defecto de 30 segundos, lo que implica que si el comando no termina, se dispara un error. Claro, ahora todo coincide ya que seguramente la ejecución del stored procedure dura más de 30 segundos, lanzándose la excepción nada aclarativa recibida. ¿Solución? Establecer un valor más alto para dicho timeout. Aunque no se recomienda tocar este parámetro ya que es difícil que la ejecución de una query o stored procedure dure más de 30 segundos (excepto en las monstruosas transacciones y procesos batch que realizan bancos y demás), esta vez vamos a añadir una simple línea de código C# asignando un valor entero muy alto al timeout del command, pa' cubrirnos las espaldas ;-). Compilamos, y ¡allá vamos de nuevo!
Compilamos, y ¡allá vamos de nuevo! ¡Voilá! Como se puede apreciar en la imagen de arriba, las 100000 inserciones se han realizado perfectamente, en un tiempo ligeramente inferior a las 100000 inserciones realizadas "a pelo".
¡Voilá! Como se puede apreciar en la imagen de arriba, las 100000 inserciones se han realizado perfectamente, en un tiempo ligeramente inferior a las 100000 inserciones realizadas "a pelo".Como adelantaba al principio del post, aunque en este caso particular el ejemplo se ha desarrollado con el conector de .NET para MySQL, esto mismo sirve para otros conectores, tanto a MySQL, como a Oracle, SQL Server, Sybase, o el repositorio de datos que sea. De hecho, si no me equivoco, todos los conectores a base de datos vienen por defecto con un timeout por comando de 30 segundos, tiempo más que suficiente en el 99.99% de los casos, y si no anda Lonifasiko por ahí cerca con ganas de marcheta ;-).
Tened en cuenta por tanto que el timeout en los accessos a base de datos existe, y aunque rara vez se da, hay casos en los que se supera y es necesario reajustar su valor manualmente por código. Soy el primer timeout-breaker, o ¿tiene alguien alguna otra experiencia similar que contar con otro conector hacia MySQL o hacia otra base de datos? Seguro que sí...
SaludoX.










8 comentarios:
Tengo una duda: Cuando el comando se cancela, a los 30 segundos: la BD vuelve a su estado original? (es decir, 0 inserciones); continua hasta el final? (es decir, 100000 inserciones); o se para donde iba? (p. ej. 40.000 inserciones)
Muy buena pregunta, y me temo que la respuesta no te va a hacer demasiada gracia, como a mí: para mi sorpresa, el conector o la BD no hacen rollback de una operación de timeout, con lo que la BD queda en un estado bastante inestable, con los registros insertados hasta el momento del timeout, en tu ejemplo, 40000.
Supongo que es cuestión de implementar cada opción (tanto la opción stored procedure como la opción query de texto) dentro de una transacción, con su coorrespondiente commit y su pertinente rollback en el catch de la excepción, pero para nada comparto este enfoque y comportamiento de dejar la BD "a medias" tras un timeout. ¿Sabéis si ocurre con otros conectores u otras BDs lo mismo?
SaludoX.
SaludoX.
Jo, si es que sois unos brutos... :) La verdad es que no te equivocas, el timeout establecido en los conectores para la ejecución de un procedimiento almacenado o un comando es de 30 segundos. El valor puede cambiarse, como bien indicas. Por ejemplo, en objetos ADO atacando a conexiones de SQL Server se conseguiría mediante un objSQLCommand.CommandTimeout = 180, y con JDBC atacando a Oracle podríamos hacerlo, por ejemplo, mediante Statement.setQueryTimeout().
En cualquier caso, no es muy recomendable alterar esos valores, porque podemos mantener la base de datos trabajando demasiado con algunos comandos que, posiblemente, podrían optimizarse. En cuanto a la inconsistencia que has encontrado en el pseudo-rollback que lleva a cabo MySQL (que en este caso es prácticamente nulo), no me he encontrado con situaciones similares con esa u otras bases de datos... pero tampoco he ido con tan mala saña contra ellas, jejeje.
Habrá que probarlo ;)
¡Saludos!
La verdad es que se me había pasado comentar en el post el "no rollback" de este tipo de operaciones contra BD que desencadenan un timeout, pero Josu, ha andado una vez más muy agudo y ha levantado la liebre "bien levantada". Lanzo la piedra: ¿Será cosa de MySQL o cosa del conector? Sea quien sea, es realmente grave, o por lo menos a mí me lo parece. Como bien dices Mithdraug, esto hay que probarlo contra otras BDs u otros conectores...
PD: Por si no lo habéis notado, me encanta "hacer de usuario cabrón" para comprobar cuánto aguanta un sistema, una web, un framework, una BD, etc. Se aprende un huevo...
SaludoX.
Saludos.
Necesito una pista aceca de un problema.
Estoy usando el conector de MySQL con c# pero en linux usando mono.
En windows PIV 1.8GHz 1G RAM funciona bien pero en un Debian Etch PIII 128M RAM 633MHz cuando hago una insercion funciona pero cuando un while con 1000 o mas a veces funciona y aveces se queda colgado, no tira ningun error solo se queda colgado. Incluso probe a parar el servidor mySQL a ver si lanzaba algun error pero ni aun asi nada.
Probe lo del time out command y lo baje a 10 a ver si me lanzaba algun error y mada.
Alguna pista...
Buenas @edwinspire,
No sé cuál será el comportamiento ni el estado de desarrollo del conector de MySQL para Mono, aunque doy por hecho que a nivel interno, su funcionamiento debería ser el mismo que MySQL Connector for .NET.
Por ello, aunque seguro que ya lo has probado, más que bajar el tiempo del timeout del command para ver si el conector te lanza un error, yo subiría el tiempo estableciéndolo por ejemplo a Int.MaxValue. Prueba eso para ver si le da tiempo a completar las 1000 inserciones.
Así todo, es muy raro que pares el servidor de MySQL y el conector no te lance ninguna excepción. Doy por hecho que utilizas el pertinente bloque try/catch/finally, también te recomiendo la cláusula "using" para gestionar la conexión a BD, que ella solita se encarga de abrir y cerrar la conexión.
No sé, prueba todo esto, pero también podría ser que el conector de MySQL para Mono tuviese algún bug...
PD: Doy por hecho, que con 128 MB de RAM en la máquina, estás trabajando contra un MySQL remoto..., porque si desde luego lo tienes en local, puede que el problema sea que la BD no "tira".
SaludoX.
Saludos, bueno ya descubri cual era el problema con la conexion MySQL que se quedaba colgado el programa, se trataba de la version de Mono, en mis pruebas las hice en WinXP con mono 2.0 mientras en Debian tenia instalado la version 1.9.x, actualice la version en Linux y ahora funciona como deberia.
Buenas edwinspire,
Me alegro mucho de que el tema de las inserciones en bucle se haya solucionado actualizando la versión 1.9.x de Mono para Linux a la versión 2.0, seguro que había algún tipo de bug en las clases de acceso a datos de MySQL.
Muchas gracias por compartir la solución con el resto de lectores.
¡SaludoX!
Publicar un comentario